
In this challenge, we have a website with captcha. Base on the question, we need to solve 500 captcha within 10 minutes. Very easy right?
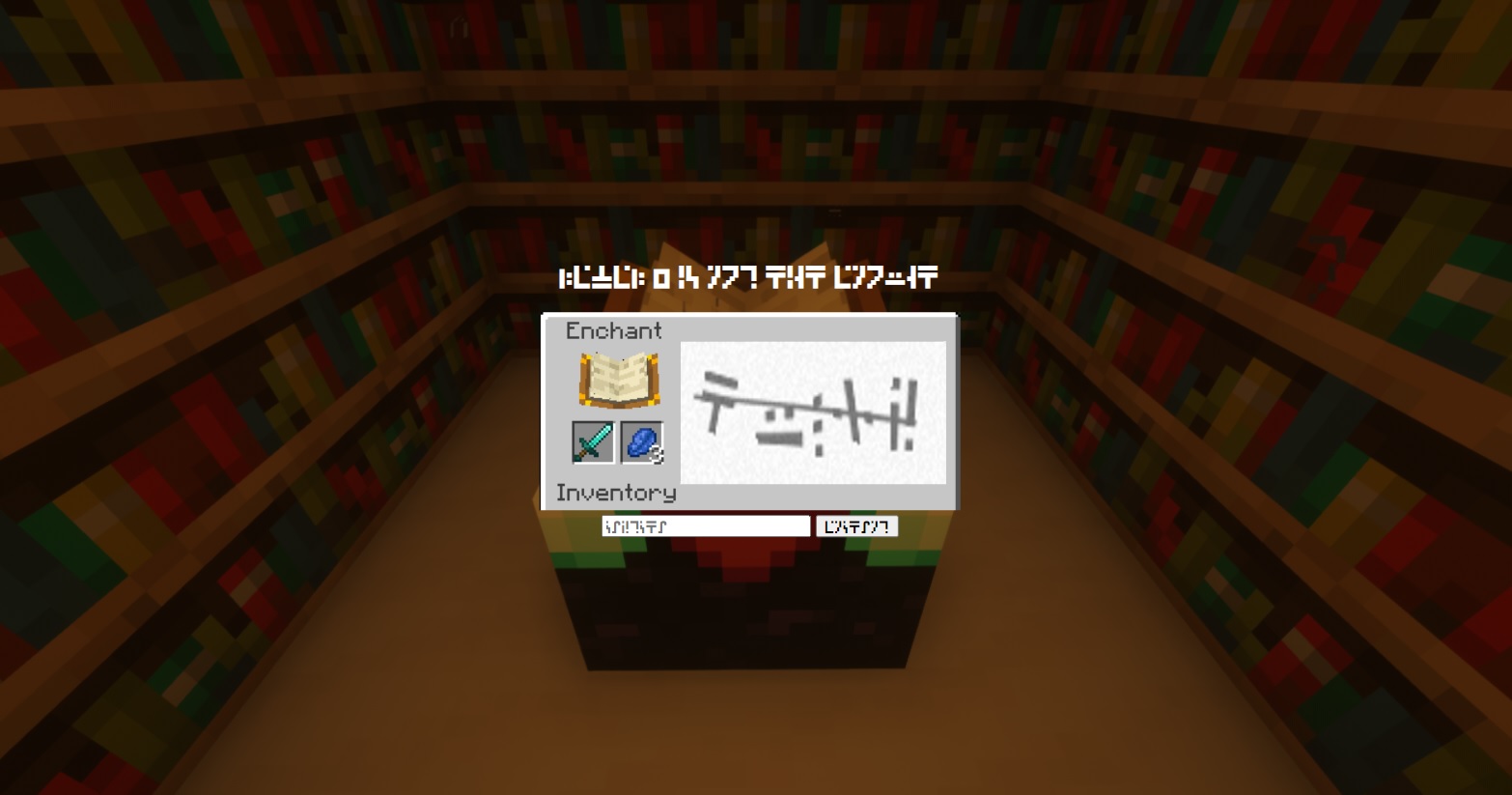
However, the language of this captcha is the Standard Galactic Alphabet (Minecraft enchantment glyphs).
The character mapping:

From the source code, there is a curious comment:
<!--TODO: we don't need /captchas.zip anymore now that we dynamically create captchas. We should delete this file.-->We are able to obtain ~70k samples here provided by the challenge author.
This is one of the sample captchas:
With this dataset, I think everyone can think of using neural network to solve this challenge (I guess MNIST or captcha solving should be the first example you run in deep learning course, right?)
From my experience, I know that it may not a good idea for me to debug/tune a neural network for doing computer vision work during a CTF. After some trial and error, I come across with this excellent github repo cnn_captcha. I also received a interactive script from my god like teammate @mystiz613.
In order to use this code, you need to setup the config file (conf/sample_config.json) properly. This is my configuration:
{
"origin_image_dir": "/home/xxx/solve/captchas/",
"new_image_dir": "/home/xxx/solve/new_train/",
"train_image_dir": "/home/xxx/solve/train/",
"test_image_dir": "/home/xxx/solve/test/",
"api_image_dir": "sample/api/",
"online_image_dir": "sample/online/",
"local_image_dir": "sample/local/",
"model_save_dir": "model_v8/",
"image_width": 250,
"image_height": 75,
"max_captcha": 5,
"image_suffix": "png",
"char_set": "ABCDEFGHIJKLMNOPQRSTUVWXYZ",
"use_labels_json_file": false,
"remote_url": "http://127.0.0.1:6100/captcha/",
"cycle_stop": 20000,
"acc_stop": 0.99,
"cycle_save": 500,
"enable_gpu": 1,
"train_batch_size": 32,
"test_batch_size": 32
}First attempt
With one GeForce RTX 2080, I can train up a model with 99% accuracy within 1.5 hours. Here I didn't do a proper separate of train and test sets, but turns out this model saved me a lot later...
This model mostly end up in level 30 to 40 and start to fail. Anyway, it is normal. With a 99% accuracy, we only have 0.6570% to survive up to lv 500 🙁
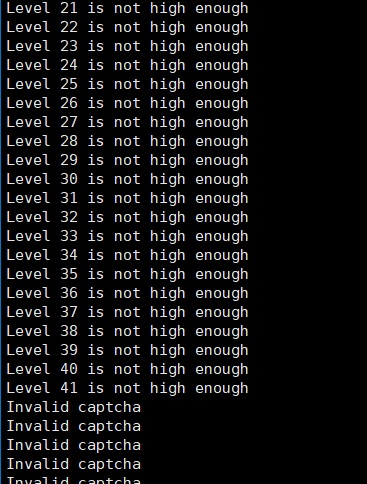
Second attempt
Here, I think of Ensemble Learning.
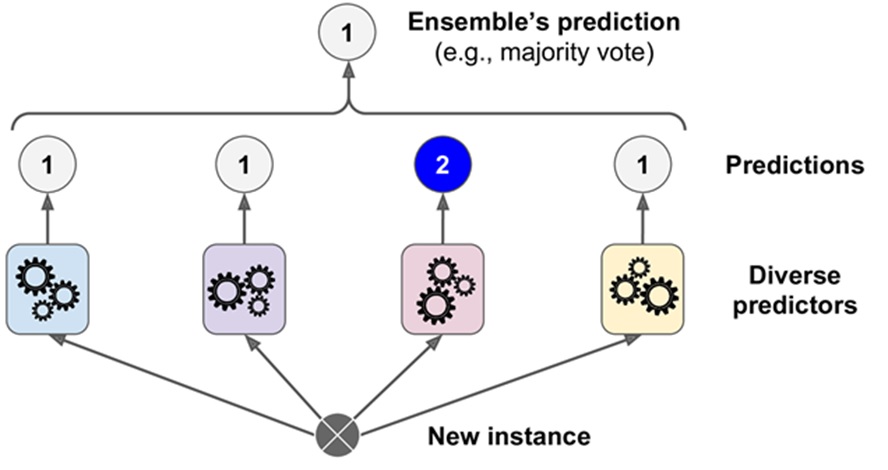
The idea of ensemble learning is very simple. Assume we trained multiple classifer for the same classification problem, we create a classification base on multiple classifier to our input. We apply a similar concept here, but we hope any one of them could solve the captcha even the previous model fails to do. Originally, we think of bruteforce the top 2 decision of each character, but turns out it requires 32 query, which we may run out of time...
To train up different models, I tried to play with the different parameters like batch size, size of evaluation set and different training set, etc.
I also collected extra dataset by save those captcha we solved with only 1 model and denote as good set, those with more than 2 models as benign set. We feed these data to our training script to train new model and deploy it to collect more new samples. In total, we collected 120k samples and trained 8 models through this iterating process.
The strategy for adding new samples to the dataset as follows, we tried to extend our dataset upto about 90k with both good set and benign set. And the last 20k is from the benign set. We also trained several models with different numbers of data samples during our data collection procedures.
The best result with five models is 169 levels, while I can attain reach level 225 with eight models. For 5 models to 8 models ensemble, we improve from solving 40 level before fail to average solving 60 level. However, it still very far away from solving 500 within 10 minutes.
At the end, my god like teammate @mystiz613 come up with an idea to solve as a hybird approach (DL model + human)... That is, if a captcha can't be solve with 8 of my models, I will do it myself...
After 3 trials (once timeout at 495 lv, once at 365 lv), we succesfully capture the flag with ~90 second left by luck (manually solved ~10 times in total)...
Level 497 is not high enough
Invalid captcha
Invalid captcha
Invalid captcha
Invalid captcha
Invalid captcha
Level 498 is not high enough
Level 499 is not high enough
uiuctf{i_knew_a_guy_in_highschool_that_could_read_this}Credits
90% of work from @mystiz613, 10% from me.
Reflection
I guess there are better way to solve it with full automation right? After submitted the flag, I tried to do cause analysis why is such hard to solve with full automation (I know that I am too weak, please don't laugh at me 😭). These are my observations:
Duplicate characters
Continuous duplicate character is hard to solve with my model.
JGGSS:

YJKYY:
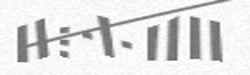
J, R, P and Y
Due to similar shape to other characters or is formed by more than 2 components...
YJKYY:
JPSCB:
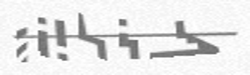
FDSEJ:
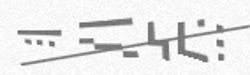
VJGJJ:

Similar glyphs
In fact, most of cases I solve manually the edit distance is between 1-2 characters and the problematic region are share by different models...
For example PTJYZ:
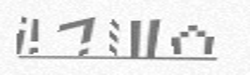
Option available:
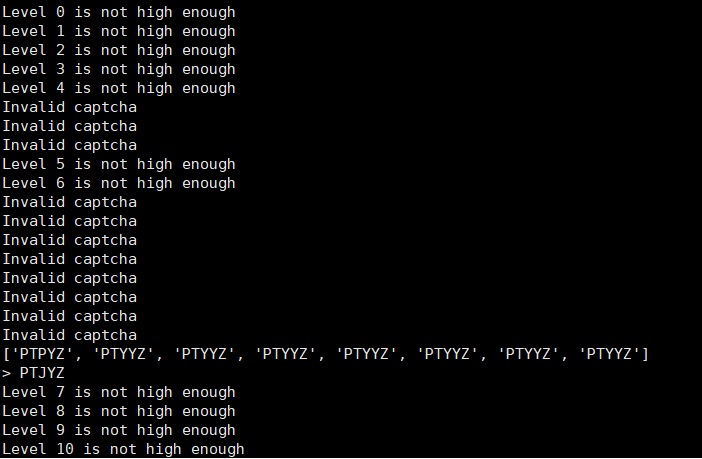
That is it! Thanks for reading! :)